

Computer science team wins challenge to improve reading process of reviews
Social media allows every one of its users to become a critic. So how can a reader discern the good from the bad or the key words found in a long diatribe or a perfume-laden endorsement?
A team of computer science graduate students led by Christopher North, and Naren Ramakrishnan, professor, both in Virginia Tech's Department of Computer Science, have answered this question, and in the process won a competition. Ramakrishnan is also the director of the Discovery Analytics Center.
The other winners were from Carnegie Mellon University, Stanford, and University of California at Berkeley.
The Virginia Tech team entered a competition sponsored by Yelp, the generator of a free app for mobile phones that finds local businesses from restaurants to medical professions. The app allows for reviews of the various businesses. However, if one visits Yelp's homepage, the reviews attached with each listing can be in the hundreds or even in the thousands.
"Using these user-generated reviews have become important reference material in casual decision making, like dining, shopping, and entertainment," Ji Wang of Shanxi, China, said. "But the very large number of reviews make the reading process time-consuming." Wang is now a Ph.D. candidate working with North. This award-winning work was part of his 2012 master's thesis, also advised by North.
So, Wang, and Sheng Guo of Jiangsu, China, a Ph.D. student advised by Ramakrishnan, along with Jian Zhao, of Jilin, China, a graduate student collaborator at the University of Toronto, also advised by North, decided to find a way to develop a better method of summarizing text through the mining or retrieval of key data. The objective was to help guess a review's rating from its text alone. The colleagues created a computer program that allowed them to cluster specific types of words to summarize the product reviews. Their winning entry in the Yelp dataset challenge competition produced a parsing of the words found in a customer's review of a business. Then they were able to infer relations from the text that would guide users to more insight and pertinent information.
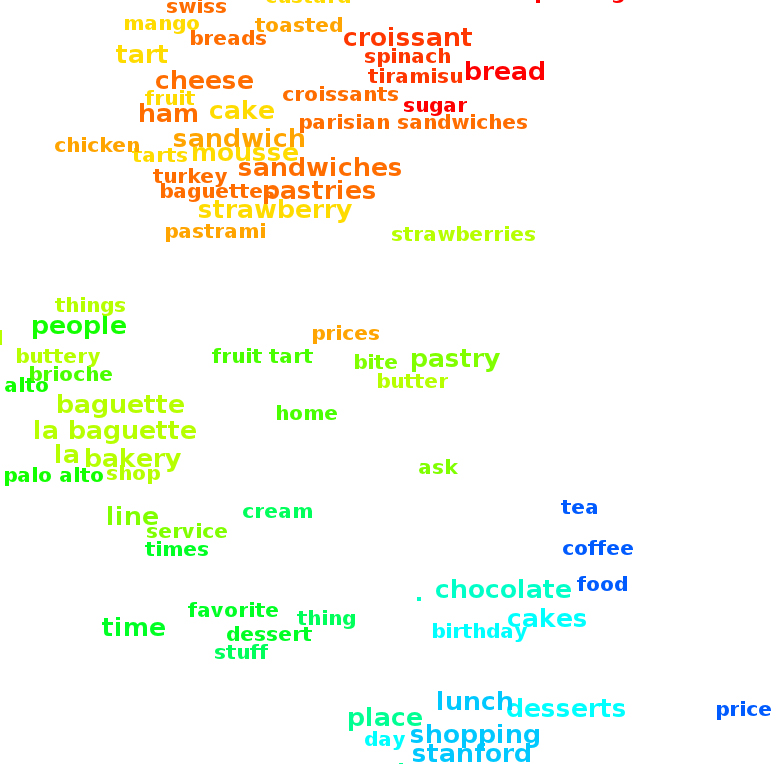
As an example, if one reviewer spoke at length about an experience at an area restaurant, the Virginia Tech team used grammatical relations such as the noun and the verb in a sentence, and the relationship of the words to form a context graph from the user's review. All the words in a review might be boiled down to just three: La-Baguettes, sandwiches, best. And in doing so, eliminate words such as order, mustard, variety, onions, friends, experience, etc., that might be considered superfluous to the user's need to know for making a choice.
Wang explained that the team was able to embed the semantic information of a grammatical dependency graph into a word cloud. "Our specific word cloud is designed to provide more insight about user generated reviews by creating clusters based on semantic information," Wang said.
"Word clouds, also called tag clouds, are very popular text visualization tools. They provide the frequency data of a variety of text sources and encode the frequency into the word's font size," Wang said. "The clustered layout cloud we developed embeds semantic information to the clustered layout to present the review content."
North believes his students' work represents the first attempt to use real reviews for a clustered layout word cloud.
"In the future, we plan to add more information on the clustered layout word cloud, such as time-series restaurant reviews and some emotional analysis of the reviewed information. We will also apply a more advanced natural language processing technique in computer science to review the content data, as well as enable a search box function for finding words easier within the word cloud," Wang explained.
The team also hopes to add more interactions to this technique. Users can modify the natural language processing results, visualization results, and even raw data by interactions in order to obtain the customized visual analytics results they need. Users' feedback can steer the algorithm to produce more customized word clouds," Wang added.

